At my day job my colleagues and I develop a data gathering and visualisation platform that has a fair bit of Python behind the scenes.
We test a lot of this Python using pytest and all our tests are run by a large locally hosted instance of TeamCity.
A test run involves TeamCity executing a bash script responsible for setting up any test dependencies (usually Docker containers) and then executing the test itself (also usually a Docker container).
Problem
My interest was piqued by one of my colleagues trying to understand why a particular long-running end-to-end test had suddenly started failing part-way through with seemingly no relevant changes to any nearby code.
TeamCity gave us some clear information as to when the trouble started:
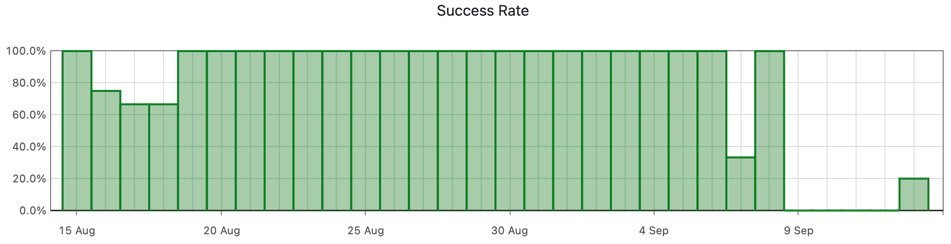
The TeamCity build log doesn’t show a lot beyond the test
execution suddenly stopping with an ominous Killed message:
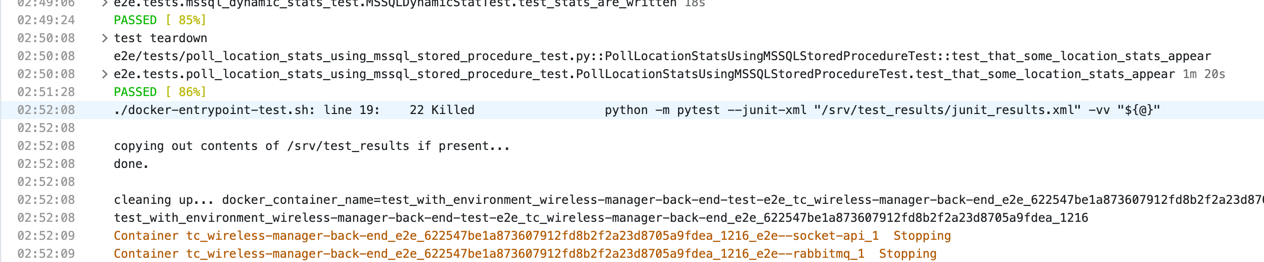
Enabling “Verbose” mode in the build log output for TeamCity gives us a little more context and clarifies that the test container died suddenly:

First thoughts
Leaning on some prior knowledge, I’m reasonably confident of the following:
- The stdout of a process will read
Killedwhen some other process kills a process (such as the kill command)- This was observed in the build log
- TeamCity will show related
stopand possiblekillDocker events preceding adieDocker event if the container was requested to stop (such as using the docker stop command)- This was not observed in the build log
When things get killed at random, my mind immediately goes to the Linux OOM Killer (a function of the Linux kernel dedicated to identifying and killing memory hogging processes).
Processes running inside Docker containers on Linux are namespaced to achieve what feels like isolation to the process in question; to the OOM Killer though, a process is just a process and if it’s using too much memory it’s going to get killed to save the system.
Digging deeper
Unfortunately the TeamCity runner VMs had all been rebooted (redeployed in fact) since the last failing test run as part of some ongoing improvements to our CI system and so any incriminating dmesg logs were long gone.
Fortunately we have some long-term metrics as part of our Grafana / Prometheus / VictoriaMetrics deployment that shows some OOM Killer activity for that particular TeamCity runner VM:
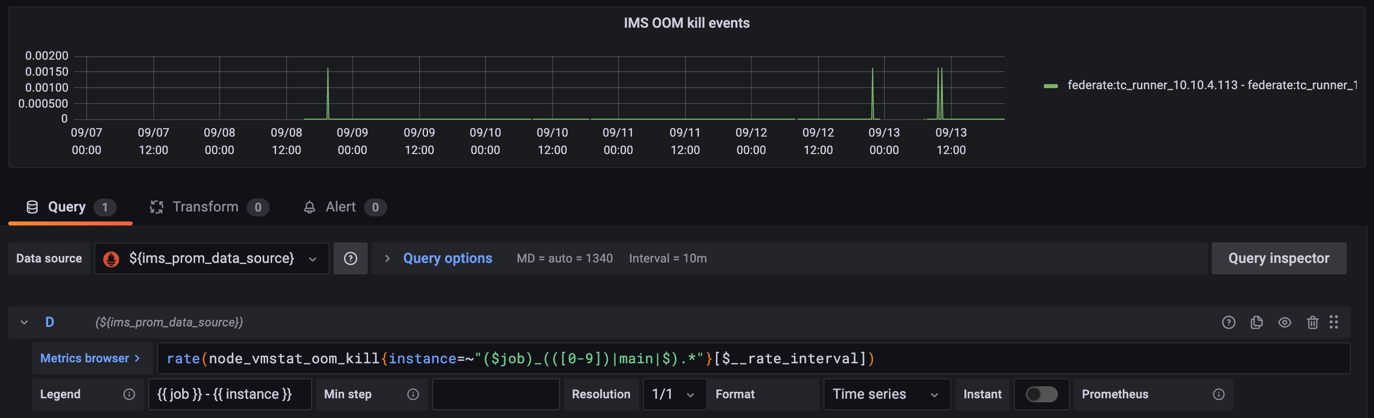
While not exactly a smoking gun, it definitely suggests that we run out of memory on that (and probably all) TeamCity runner VMs from time-to-time.
Here are the specs for that VM according to our Proxmox cluster:
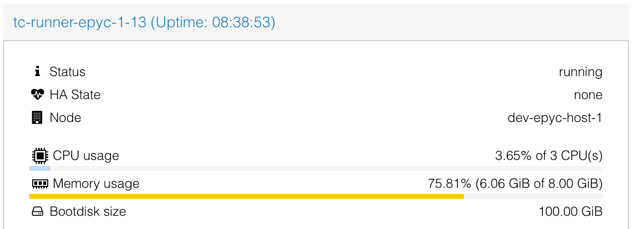
You’ll have to trust me on this next statement as I didn’t grab a screenshot: there was no swap configured- this is relevant, as depending on the amount of memory needed and the amount our test was likely to be affected by bad performance, having swap configured could potentially absorb memory leaks and permit our test to pass.
Recreating the problem
With a strong hypothesis formed, it’s time to set about proving it- not wanting to spend much effort on potentially throwaway scaffolding, I decided just to run the test locally (in Docker, but for macOS) and just watch its memory usage in the meantime.
That looked a bit like this in htop (note the memory percentage increasing, excuse the GIF encoding):
After some quick Googling on how best to do memory profiling on a Python process without having to edit the actual code I came across memray which appealed to me for two reasons:
- I could use it as a wrapper to execute my tests
- It has had recent commits
Installing and running it was a trifle:
pip install memray
python -m memray run -o output.bin \
-m pytest -vv e2e/tests/socket_api_vs_db_stat_import_server_test.py
After the test completed, memray tells us what to run to generate a flamegraph that we can
then open:
python -m memray flamegraph output.bin
open memray-flamegraph-output.html
The result is quite interesting:
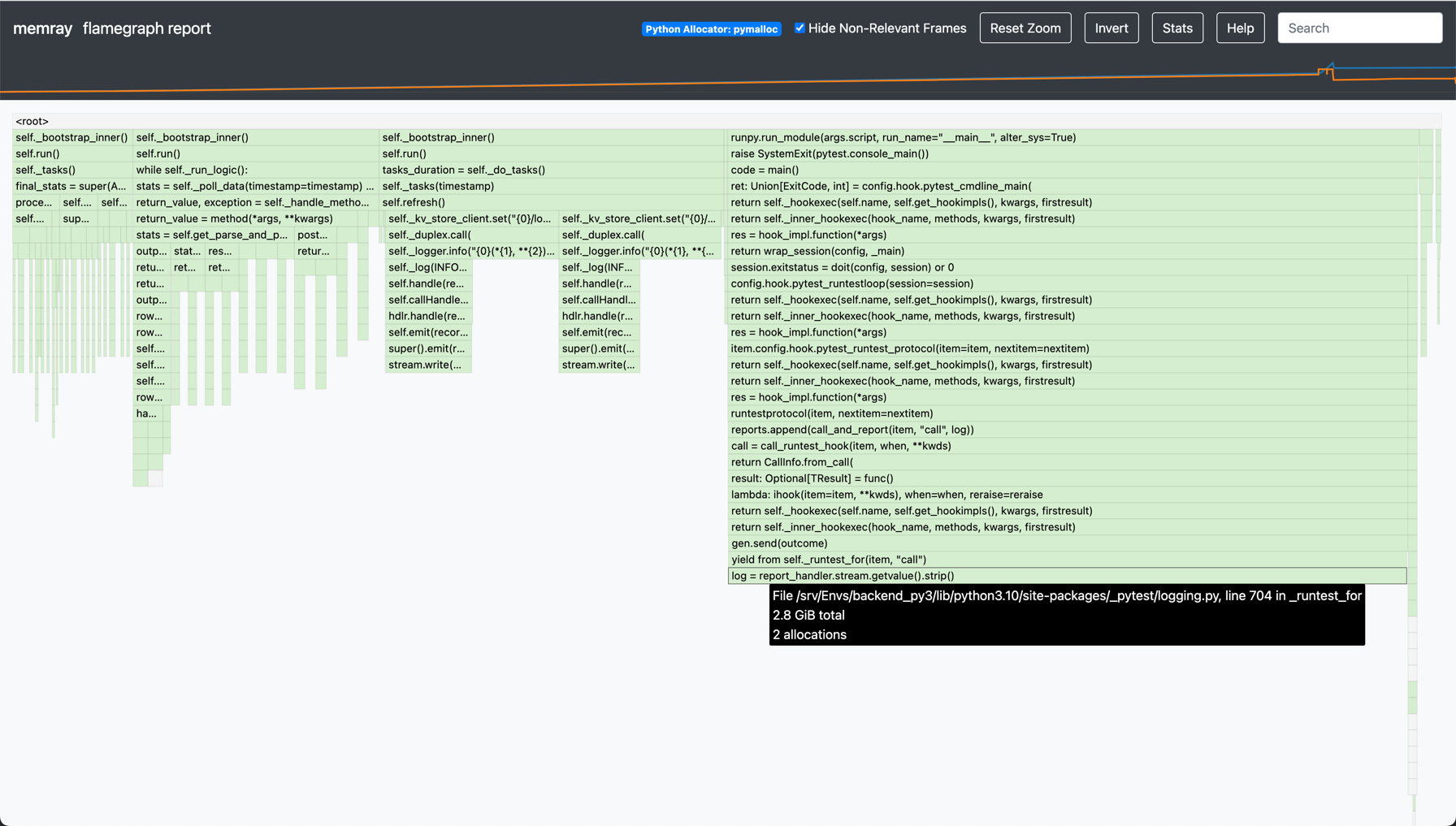
We can see that the largest 3 items are all related to logging; there’s nothing particularly interesting about the way we do logging (but we do a lot of it)- the items in question are some of the larger log entries (e.g. dictionaries being repr’d).
If we check the summary to see the overall damage:
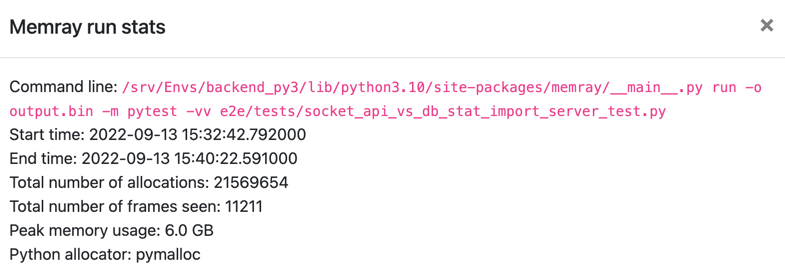
Oh it’s bad.
It’s at this point I recall
that pytest keeps tracks of all Python loggers and includes
their messages in the test output (something I’ve intentionally disabled before in favour of live-logging to get context on long-running
tests)- could it be that the sheer volume of log messages and the extended duration of the tests is using up all the RAM?
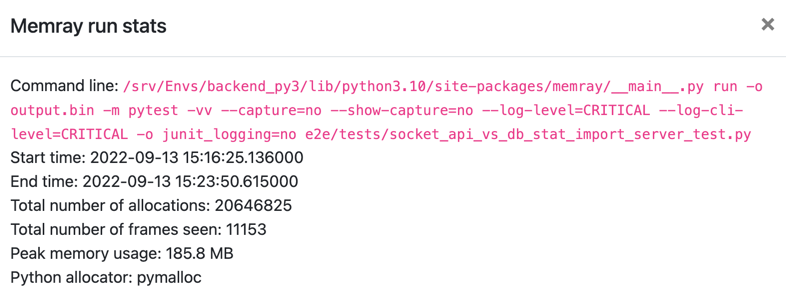
Testing the hypothesis
This is simple enough- we just have to re-run the test with the log capturing disabled (you probably don’t need all of these flags, but my
initial attempts with just --capture=no didn’t work so I went scorched earth with the flags):
python -m memray run -o output.bin \
-m pytest -vv \
--capture=no --show-capture=no --log-level=CRITICAL \
--log-cli-level=CRITICAL -o junit_logging=no \
e2e/tests/socket_api_vs_db_stat_import_server_test.py
python -m memray flamegraph output.bin
open memray-flamegraph-output.html
The flamegraph shape more closely represents the work being done (lots of serialisation of data between Go and Python):
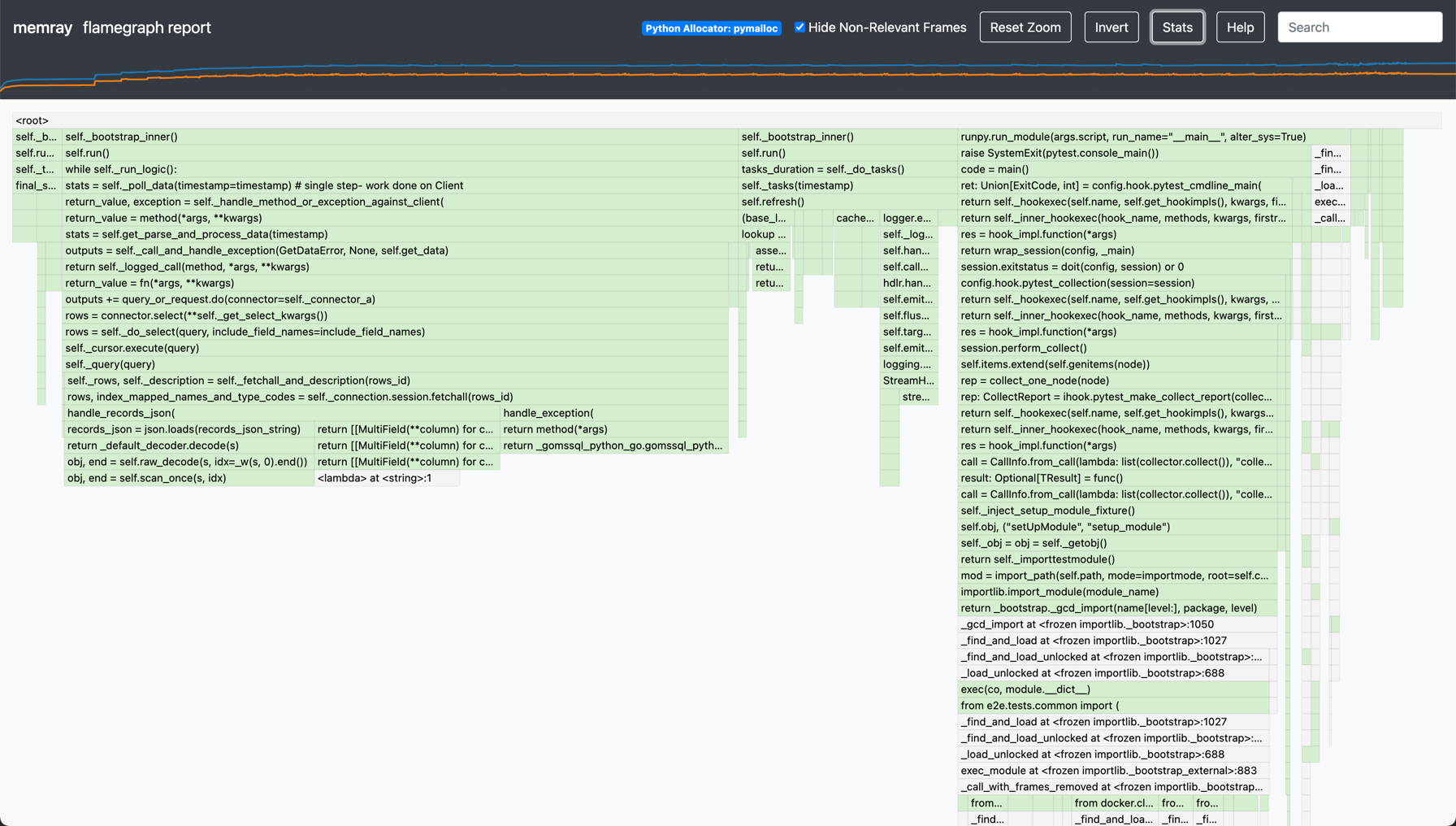
And the summary reflects far less memory usage:
Catalyst
The reason this suddenly became a problem was a result of the CI improvements I spoke of earlier; we’re in the process of breaking out one very large TeamCity runner VM into several smaller VMs (to try to prove a hypothesis that the QEMU virtualization is slow for storage).
So practically the RAM ceiling was dropped such that this memory leak became problematic (rather than just being absorbed as it had been for a long time).
Resolution
With a pretty clear cut smoking gun, we can set about fixing the problem; here are a few options available:
- Inside our platform
- Remove or edit those large log entries (if they’re not useful)
- Stub out the logger with a dummy logger (not actually a logger for
pytestpurposes but feels like one to our code)
- Outside our platform
- Change to another Python test runner
- Just disable log recording (as we did to test the hypothesis)
For this particular situation, the logs caught by pytest are not that useful- they’re usually just logs showing repeated RPC failures or
empty query / request results while waiting for them to be non-empty, so it’s acceptable to simply check-in the extra pytest flags for
disabling log recording and call it a day!