So it’s been about 2 months since I last wrote about this thing and it had been running for a couple of weeks before I wrote about it, which means it’s been operating for maybe 3 months all up.
Despite a few initial teething issues, I have to say it’s been pretty good (and definitely less maintenance than my old setup was).
Here’s how it looks at the moment:

As you can see, cable management is my passion.
I’ve even gone as far as setting up some monitoring:
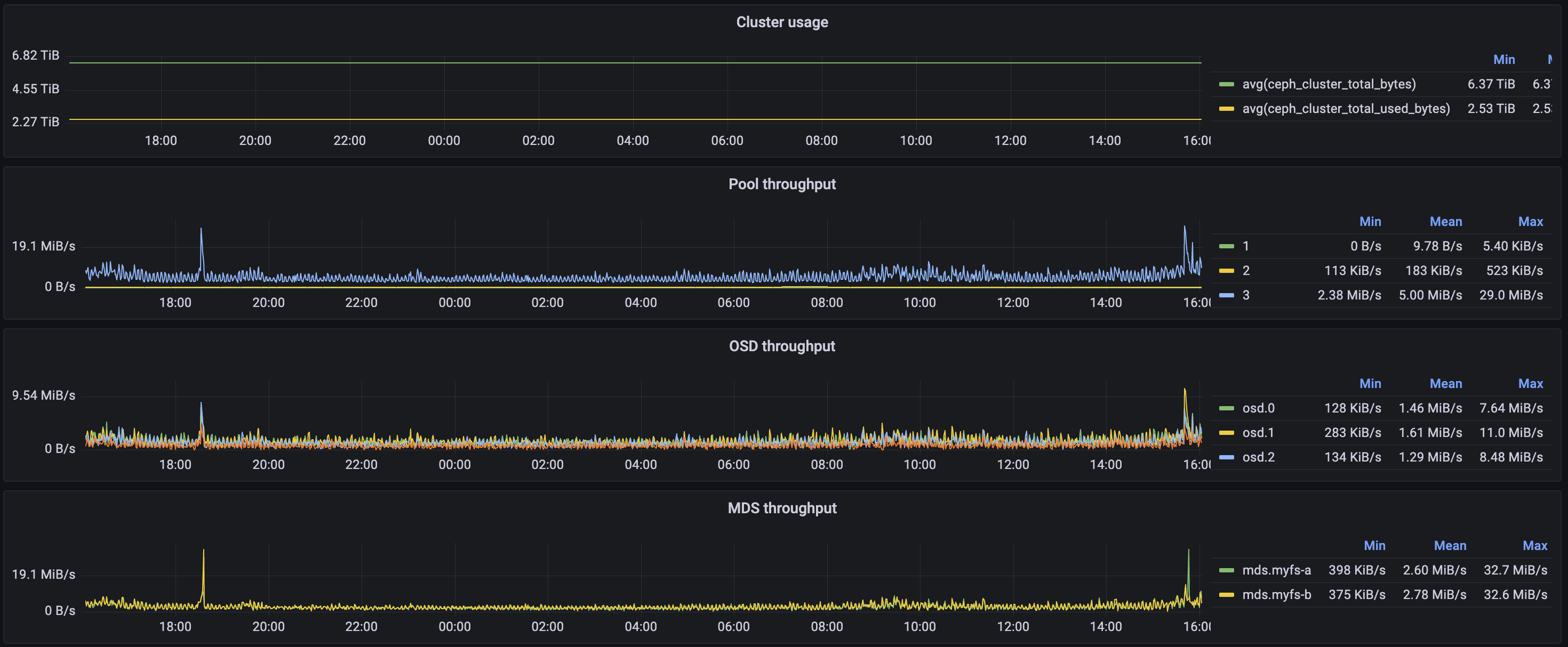
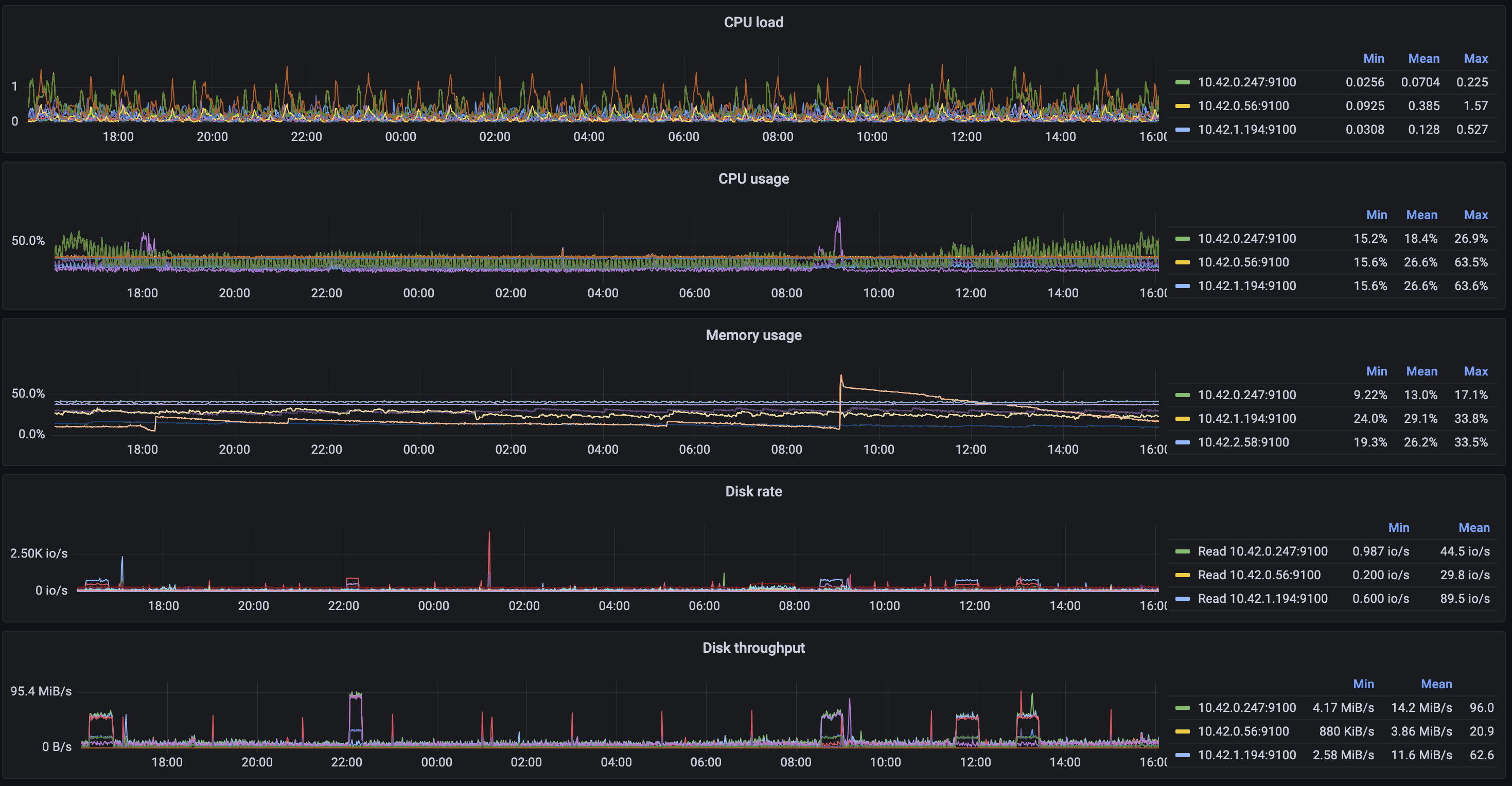
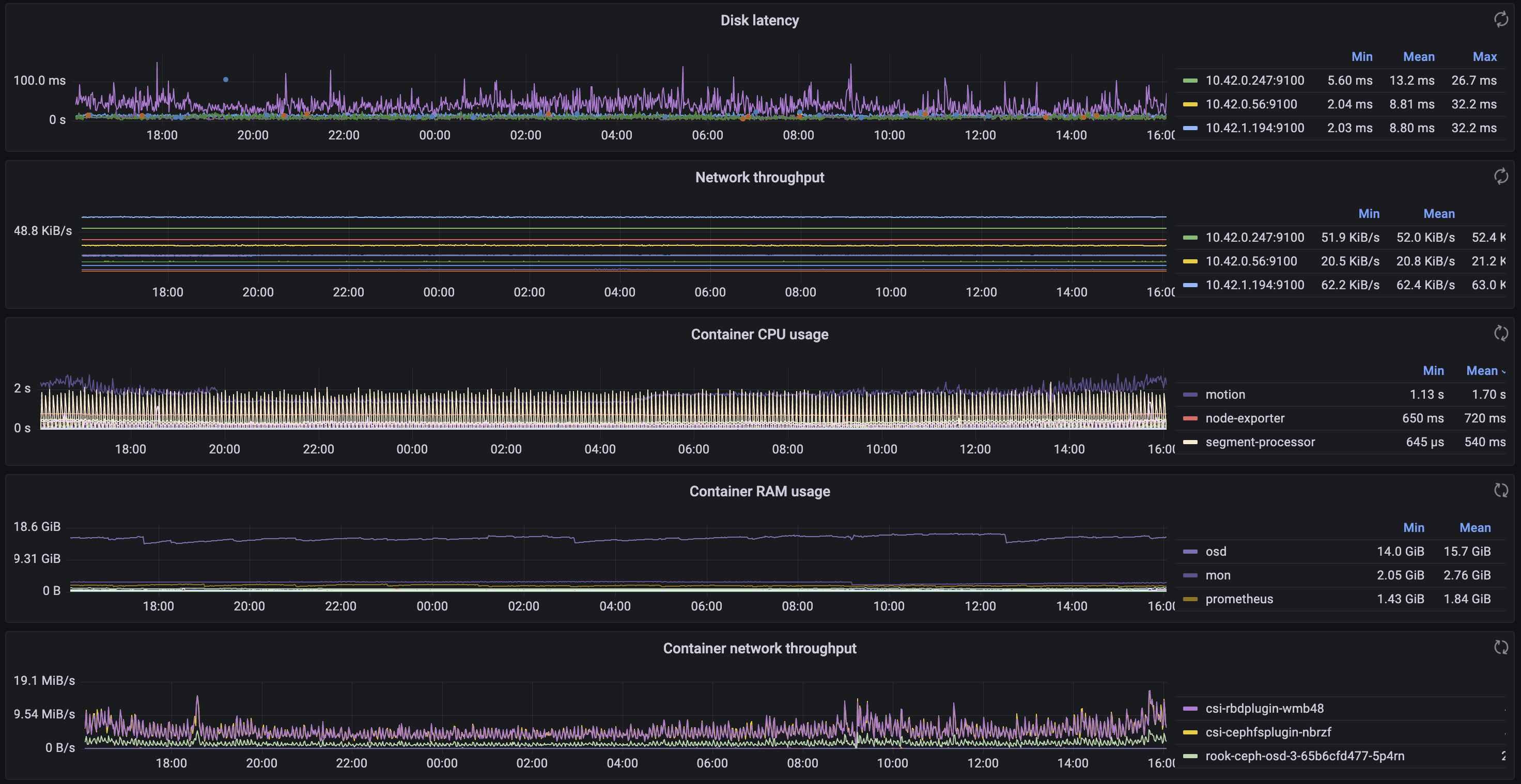
Promscale is dead, long live VictoriaMetrics.
Learnings
It hasn’t all been sunshine though; here are some of the things that went wrong…
User error
While trying to fix some Ceph-related issues, I thought I could safely just blitz the whole rook-ceph namespace and redeploy it, expecting
everything to just pick up where it left off because the identity of the storage cluster is on the physical disks, right?!
That was an incorrect assumption- probably my files were still there, locked away in the numerous layers of abstraction and spread across my nodes, but all of the context around how to access them was long gone when the Persistent Volume Claim was deleted.
So I had no choice but to make peace with an enforced spring clean of my old garbage files; fortunately nothing important, a week or so of CCTV footage and some scanned documents that only needed to live long enough to email them out).
Swap configuration
If you’re a Kubernetes OG you may be of the mindset that
a Kube node should not have swap configured thus
enabling node-pressure eviction based on MemoryPressure
and then all of your ridiculously vendor-locked automation can spin you
up a new Kube node faster than you can say “credit card”.
Unfortunately if your cluster is managed by yourself and not by Uncle Jeff, losing a node isn’t something that automatically resolves itself for a fee, it’s quite an inconvenient problem because now you need to physically access your nodes in order to restart them (a significant inconvenience requiring a ladder if, like me, you thought it was a good idea to put your cluster on a shelf above your fridge).
My experience was that for reasons I would find that one or more of Kube nodes would completely lock up (after exhausting all their memory) and because there was no swap, the Linux kernel had quite literally nowhere to put the unused stuff in order to try and recover the situation with a healthy bit of OOM Killing and so everything fell in a heap.
Fortunately for me, I discovered that recent versions of Kubernetes actually have support for nodes with swap memory enabled; after re-enabling swap on all my nodes, suddenly my problems just disappeared- so I guess the lesson for me here is to second-guess what seems like conventional wisdom when it’s telling me to do things that I wouldn’t otherwise do (because in all non-Kubernetes cases I would always have swap, I just underestimated my own actual experiences in that department and overestimated the dated Kubernetes guidance).
Watch all the dogs
I don’t really actively develop cameranator any more (short of the recent UI refactor); since forever though it’s had this odd bug where parts just hang up randomly- I’m pretty sure it’s not my code, because I see it in the Segment Generator (which is just some orchestration I’ve written around ffmpeg) as well as in Motion.
The common theme? They both touch the GPU… and they both use ffmpeg underneath- so probably the issue is ffmpeg. Side note.
I tried to upgrade everything to be using later versions of ffmpeg, I failed miserably and decided it wasn’t worth my time; so what else can I do?
Well a watchdog of course, what else!
I slapped together a way to expose liveness
and then made use of that with
a livenessProbe (
not unlike a Docker Healthcheck) so now this too is something that has
ceased to be a source of failures for me.
So what’s left?
I’m not really sure what to do next- for sure there are outstanding things, like:
- Get the Prometheus metrics from the Kube API and the Node Exporter to be using a common label so that I can relate them together
- Change from Traefik to Nginx because it’s been nice using Traefik (the default with k3s) but frankly I’m an Nginx guy and I only have so many brain cells to dedicate to knowledge about reverse proxies
- Migrate Home Assistant from Docker to Kube
- I can’t even remember why I haven’t done this yet, I got stuck on something mundane and just sort of stopped putting time into it-
might have been reverse proxy
Hostheader related?
- I can’t even remember why I haven’t done this yet, I got stuck on something mundane and just sort of stopped putting time into it-
might have been reverse proxy
- Physically tidy up the shelf
- I think I can use a document stand like this to get the laptops to take up less footprint
- Give Ceph the disks currently owned by the the ZFS pool on the HP Microserver
- The Home Assistant migration is blocking this; also I should probably buy some external caddies so that I can distribute those drives across the cluster (rather than having a huge chunk of storage on a single node)
- Migrate dinosaur from Docker to Kubernetes
- This is non-trivial because its whole mechanism is enabled through orchestrating the creation of Docker containers
- Deploy my entry for
the FTP Game Jame 2022 on the cluster
- More on this thing in the next post
Honestly though, I dunno how much of that I’ll do- I’ve achieved the secondary goal of migrating (most of) my stuff to Kubernetes and in doing so I’ve achieved my primary goal of learning about Kubernetes; for sure I don’t know everything about it but I feel like I’ve been exposed to a reasonable chunk of the capability it provides and got a feel for some of the patterns, enough to BS my way through an interview for a job with it anyway!